Hello, I’ve been trying (and struggling a lot) to write a Fuzzer (List a) where a will, most of the time, be a Record. However, I want this Fuzzer to only generate non-empty lists. I’ve read all the documentation pertaining to elm-explorations/test and I can’t figure out how to do this.
I’ve got no trouble writing Fuzzer for my records. Writing the Fuzzer for a List is also easy. But, a Fuzzer for non-empty lists seem much more difficult. I realize I must use custom : Generator a -> Shrinker a -> Fuzzer a but I fail to write a Shrinker a for a non-empty list.
Already spent 2 or 3 hours experimenting and trying to achieve this, but I’m having a hard-time. There’s this question which is somewhat similar, but I didn’t manage to get anything out of it. If someone could help me even if it’s just with the Shrinker it would be very welcome.
Yes, not sure why it isn’t as obvious as it looks once you know the answer. Something about writing tests gets your mind all in a muddle. But once you get past this you realize how useful the Fuzz map functions are.
In addition to the cons trick, I have also noticed that fuzz tests find more bugs with fewer iterations when they have a limited space to work in. list creates very long lists sometimes, which are pretty far from the minimal failing test cases. This is especially true if the items in the list are complex types themselves!
I commonly create a helper like this:
shortList : Fuzzer a -> Fuzzer (List a)
shortList fuzzer =
Fuzzer.oneOf
[ Fuzz.constant [] -- omit, if you like
, Fuzz.map List.singleton fuzzer
, Fuzz.map2 (\a b -> [ a, b ]) fuzzer fuzzer
, Fuzz.map3 (\a b c -> [ a, b, c ]) fuzzer fuzzer fuzzer
]
map4 and map5 exist as well, plus andMap for sequences with more than 6 items, but consider carefully how many bugs could really be present in your algorithm at larger sizes!
This is very useful @brian because I’m running into load of problems with This test failed because it threw an exception: "RangeError: Maximum call stack size exceeded" and it’s driving me crazy… it seems super random that my tests from a certain point just starting throwing this error around
@brian as an update I just tested your short list function and it doesn’t solve my This test failed because it threw an exception: "RangeError: Maximum call stack size exceeded" problem…
Maximum call stack size exceeded usually means you have a function that is not tail-recursive. Obviously, such a function can still recurse to a certain depth before going bang. If you can find the function causing the problem, will likely be fixable.
@brian Also liking your suggestion. I’ve got some tests that just take too long to run and I think it will help.
@rupert I’ve heard about the problem of having a function not being tail-recursive leading to max call stack size. However, I’ve spent sometime inspect my code (there’s around 115 modules, right now) and I couldn’t find any place where this was happening.
I’m also wondering about the following. I’m fuzzing lists of records, and the buzzers for my records look like this:
with some records having up to 12 fields or so. Do you reckon fuzzing lists of fuzzers like this can lead to max call stack size? I’m worried about the fuzzing of random strings and using stuff like Fuzz.oneOf and Fuzz.maybe leading to many branches in the fuzzing/shrinking possibilities…
In particular, those two custom functions look like this:
stringRandomLength : Int -> Int -> Random.Generator Char -> Fuzzer String
stringRandomLength min max generator =
Fuzz.custom (Random.String.rangeLengthString min max generator) Shrink.string
nameGenerator : Int -> Int -> Random.Generator Char -> Fuzzer String
nameGenerator min max generator =
Fuzz.custom
(Random.String.rangeLengthString min max generator)
(Shrink.keepIf (\str -> not (onlyHasWhitespace str)) Shrink.string)
nameCharGenerator : Random.Generator Char
nameCharGenerator =
Random.uniform '\'' (List.map Char.fromCode (List.range 65 90))
When you get the max call stack error, do you also get a stack trace? That is the easiest way to figure out where it is happening as the stack trace should name the function in the compiled javascript where it occured, and its fairly straightforward to work out which Elm function that corresponds to.
I also tend to eyeball the compiled javascript code, looking for whether it is running a loop (tail-call optimized), or calling itself (not tco).
@rupert no the only thing I get in command line after running elm-test is this: This test failed because it threw an exception: “RangeError: Maximum call stack size exceeded”`. Is there a way to get the stack trace or look at the compiled JS code for the test?
I don’t know. I think when running in the browser you do get a stack trace, but as the tests run under NodeJS it must be different there.
Sorry not to be more helpful, perhaps someone else knows? Is there some way of getting NodeJS to give you a stack trace? Or is it actually giving a trace that is somehow being suppressed by the elm-test wrapper script? Or some command line option needed to get NodeJS to be more verbose?
I just wrote a simple JS file with an infinite loop in it, and run under NodeJS, and it printed:
RangeError: Maximum call stack size exceeded
at loop (/home/rupert/sc/github/the-sett/elm-aws-codegen/src/index.js:9:8)
at loop (/home/rupert/sc/github/the-sett/elm-aws-codegen/src/index.js:10:3)
at loop (/home/rupert/sc/github/the-sett/elm-aws-codegen/src/index.js:10:3)
at loop (/home/rupert/sc/github/the-sett/elm-aws-codegen/src/index.js:10:3
So it is obviously capable of giving a stack trace that points right to call-site that broke the stack.
I see. That would be very helpful, but elm-test seems to suppress that kind of output, I guess. I’ll try looking into a way of getting such a stack trace
That does seem odd - especially as the message and stack trace are output together from NodeJS, presumably on standard error. Did the elm-test authors really go to the trouble of parsing that output to trim off the stack trace? Would be both simpler and more helpful to have just repeated it verbatim.
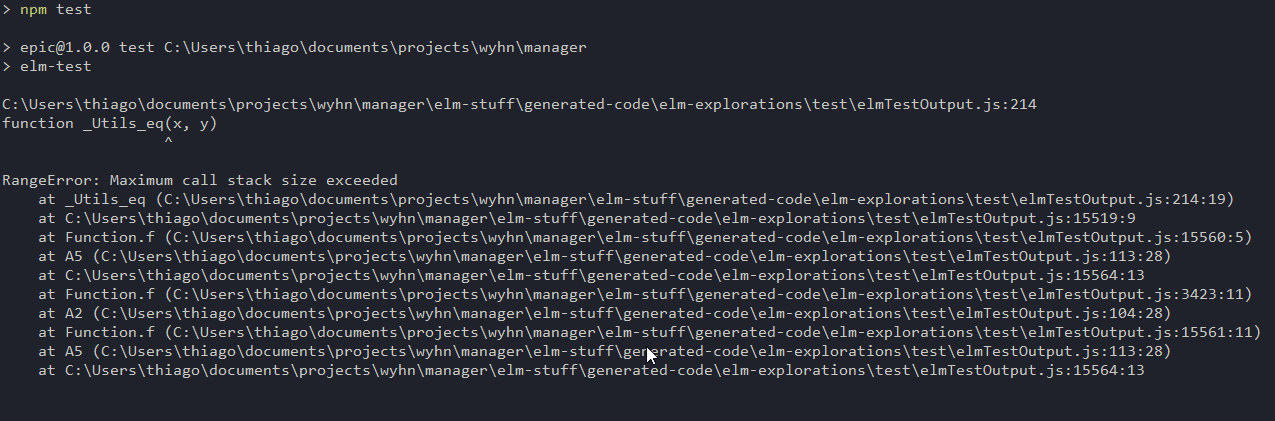
It’s really weird because I’m browsing the issues on GitHub in node-test-runner (which I believe it’s the underlying NodeJS program elm-test uses) and I found this picture:
which shows a stack trace… although this is on Windows and I’m on Mac OS
try removing the conditional from nameCharGenerator, or stripping the bad characters out with String manipulation. When you give the generator a conditional it has to retry potentially many times.
One way to get around this is to have a oneOf with valid names instead. Since these fuzzers aren’t coverage-guided, a random string is rarely what you want anyway.
Hmm, some more ideas then, based on what you’ve shared so far:
yes, it could be. Large records like this are at least going to be slow to fuzz. What properties are you trying to test here? Could they be simplified? Surely you don’t need the entire record to be random, yes? Could some fields be made constant? There is some thought that you should only write one fuzzer per data structure, but that’s not always technically feasible in our implementation. It may help you to write multiple (and carefully considering which properties in which conditions you need to test!)
I wonder if you could share the rest of the fuzzers in user? There may be something more there. In particular I’m interested in heavy branching (e.g. with mapping like you’re doing) or recursive data structures. Both are difficult to shrink and can cause these errors.
@brian I think I finally managed to solve my problem. It was indeed the large records and lists of these records using many buzzers with conditionals and shrinkers. After changing all of these fuzzers to simpler ones (e.g., strings can be a fixed size and don’t need to shrink, integers can be from 1 to maxInt and also don’t need to shrink) where it made sense – which was mostly everywhere because this data does not impact the program’s logic – I finally started to overcome the max call stack size.
I’m happy I finally understood where the problem was because I’ve been dealing with this for two months or so.
Are you aware if I shall open an issue on either elm-test or node-test-runner and report this problem regarding large records with fuzzers? I’d like to at least have a post somewhere to help other people find it easily, in case they start coming across the same issue.
Thank you all for helping on this and giving some insight!