I would love to use the Elm architecture for writing an API
I explored something yesterday that feels pretty elm-ish.
Others have also made similar things, but I have not seen this version before.
( It also has no external dependencies, just plain nodejs code. No need for npm or node_modules )
It uses elm/url package to parse endpoints and the elm/http package to create server-responses. ( Responses is then built with known constructors like Http.stringBody, Http.jsonBody or Http.bytesBody++ ) ( I first tried a solution with ports, but then one could not respond with bytes/files )
This is not complete, more an idea to how elm could be used as a microservice/API. ( The response should maybe change to be tasks or something, so that you can do calls to a http-based database before you respond )
Here is a video walking through the details on how it works:
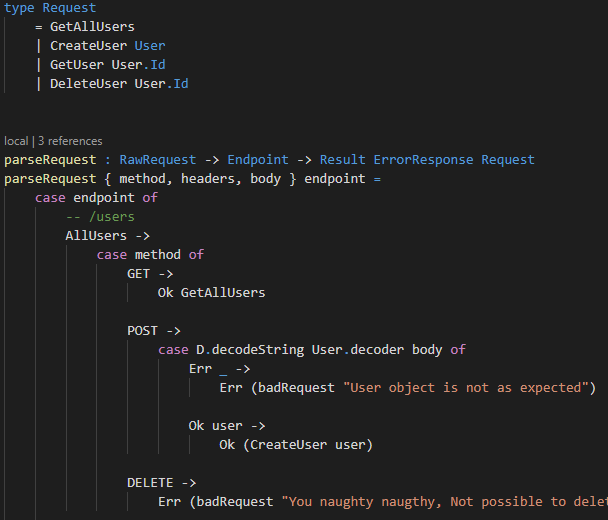
If you do not want to watch the video, this is how you write the API logic:
We parse, don’t validate. So Only valid fully parsed requests needs to be handled in update. ( The user object for create user is already parsed )
As you note, we cannot pass Bytes over ports, so that means it cannot currently do binary responses. I think in your implementation, your requests are sent over a port, so you cannot handle binary requests? There may be a workaround here, as I think File can be passed over a port, so we could use that to pass binary data?
Here is an example, parsing a URL to implement the API. I think this is a great way to describe an API:
One thing I might like to try in the future is to write something on top of Url.Parser, with a similar but extended API. Instead of just writing a Url parser, you will provide header field and body parsers too and be able to provide additional meta-data about the Url, header fields and body that you are parsing, to describe a route more completely. This meta-data could then be turned into a Swagger/OpenAPI/Whatever description of the API automatically.
One thing I like about the Url parsing approach, is that the parser for a complete API is all there together in a single block of code, and the API reads of quite naturally from it. So given some microservice implementation, I can just go and look at that code block to begin understanding it. Compare with annotations in Java code say, where the API description gets spread about the code in many places. Really nice to have the whole API parsed into a Route structure for further processing.
Correct, this does not handle binary requests, only binary response.
I had an idea to solve that by doing something like “long-polling”
So that elm always had a number of open requests with long timeouts expecting bytes or text.
And then when node receives a binary request it will respond to that long open request made by elm
I belive event-sourced microservices is a place elm would shine on backend, not for serving static content++ (I see TEA as event-sourcing on the frontEnd)
If we can find a really nice way to write these API’s, maybe, just maybe elm could be extended some time in the future to support it properly. There is no problem to solve it technically for Evan, but designing something that is as nice as elm is for frontEnd is hard ( I have no expectations that elm will support this in the future, just hopes )
A really nice way to do an API would probably be as you say defined declearative with a constructor. So that you also get automatic Swagger/documentation from that…
(The Server could even respond with a full elm-ui application (that gets the api-spec as a flag) on the /swagger endpoint with nice functionallity for test-interaction with the endpoints)
I think this might be two separate things. I do not want to use AWS (or any cloud function/serverless stuff )
Also, I want elm to do http requests and have a model by itself, not just answering client requests.
(So adding xhr support for elm-http is needed anyway)
And I would like to be able to both request and respond with binary data as well as JSON, so can not use the straight forward port solution🙁
I include a hacked XHR in elm-serverless, but it is not used for the main request/response cycle. The main request/response cycle is implemented entirely through ports. But the hacked XHR is still there, so that elm/http works as normal, when running under NodeJS.
A typical service request might be processed by calling out to some other web services - say AWS S3 or DynamoDB, or some bespoke micro-service - and that is why elm/http needs to be working.
I have a small repo with a specific approach, instead of int ids I use the request and response JS objects pair as the token that identifies a request/response. With this then you don’t have to keep a map to track requests and what to respond to.
At some point I would like to rewrite elm-serverless from scratch, and make it work along those lines.
Not for the request/response part, but for all the IO steps that may come in between. So typical API implementation might get a request, read from a database, write to a file bucket, write to a database, and then send a response.
Yeah, that is the straight forward port solution I was talking about that I tried first. Really nice if you do not need support for binary in request or response.
That looks very nice and elm-ish indeed. The update function and Messages type seem somewhat framework code to me. Would it be possible to hide those? (So the handleRequest function and Request type become the core of the API)
Definitely. You could hide them and expose a program function to use in the Main file. As a library it is trickier because of the JS and port setup but definitely doable.
This got me thinking about the difference between (1) passing the request/response pair in the request port versus (2) maintaining a Dict of requests - as elm-serverless does.
In (1) there is a single Model for the application and that is accross all requests. In @joakin s example, the model is used to keep a count.
Having a model shared accross all requests could be useful. For example if a request does some expensive computation, it could store the result in the model as a cache, and other requests could get it from there to be more efficient.
All requests are processed sequentially, as there is no parallelism in Elm.
In (2) each request gets its own Model instance, held in the Dict. Generally I don’t make use of this model, as it is simpler to pass intermediate data along with the Msgs, when there is a chain of processing done. For an example see the Msg type here: eco-server/API.elm at main · eco-pro/eco-server · GitHub
The elm-serverless package has just 1 model, not exposed to the application. Inside it there is a Dict that maps request id to the per-request model.
This means that requests can never know anything about each other. They could in fact be processed in parallel - not sure how threading working in NodeJS. But I could compile the Elm JS code using one of the the JVM javascript engines for example, and then fire up several Elm runtimes in parallel, and have an Elm HTTP server that really can process multiple requests in parallel.
Hard to know which way is better. I like the idea of a shared model for caching purposes, but it is also dangerous if you get muddled about what is in the global cache (I’m thinking of a hard to find bug that nearly delayed a major release at a bank where I worked, that was caused by global state in an HTTP server in our pipeline). The model per request approach is cleaner.
Yeah those are good questions Rupert, there are many trade-offs.
I think there could be different Server.program functions, the same way that elm-browser or elm-spa do it, going from simpler to more complex, the more complex having some sort Shared.Model like in elm-spa’s Page.advanced to allow you to keep state across requests.
For updating the requests you could force the request handler to return an Effect to update the shared model. This could even mean sharing the messages to update the global state across threads, or to a centralized thread.
Yes, If you use the elm server as an aggregate/materialized view in an event sourced system, you do not even talk to a database or file system on requests. It just reads old events/msgs on init and builds an in memory data model that can be queried, updating it on every event/msg. The way I see it, The elm architecture is more or less event sourcing, but on the frontend instead of the entire application/solution.
Message = Event,
update = update,
view = data at API endpoint
I experimented with effects modules in Elm 18, and learned that you cannot write effects over a type variable a. So in this code, you see all the types of things are explicitly listed sendString, sendFloat and so on:
I had hoped I might be able to have:
sendString : String -> a -> Cmd msg
listenString : String -> (a -> msg) -> Sub msg
So I think using effects to update a shared model is not a bad idea, and could give us a shared cache between request threads, without needing to introduce threading into the language. To make this shared model able to contain anything, most likely its type would be Dict String Json.Encode.Value, and we would need to write encoders and decoders for whatever we put in it. A bit like using local storage from Elm. I’m quite used to writing codecs now, but the extra effort does seem a bit offputing.
")



 I’ll point out 2 things though
I’ll point out 2 things though

