A few hours ago I looked at the implementation of List.map, which looks like this:
map : (a -> b) -> List a -> List b
map f xs =
foldr (\x acc -> cons (f x) acc) [] xs
however, for me it seems that foldr is not tail-call optimizable. So I tried another version:
map f =
List.foldl (\x acc -> (::) (f x) acc) []
>> List.reverse
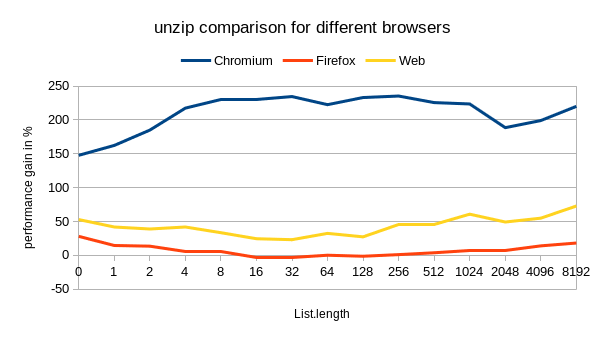
The additional List.reverse does not seem to be a problem on Firefox as the following animation shows:

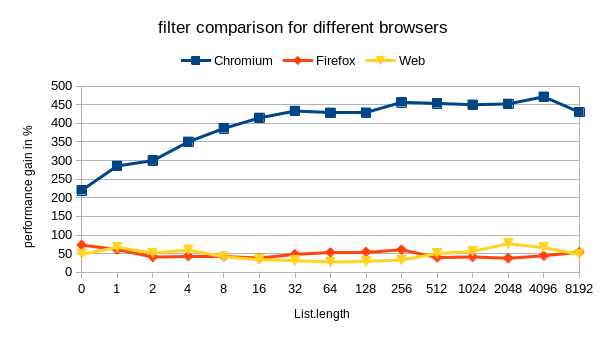
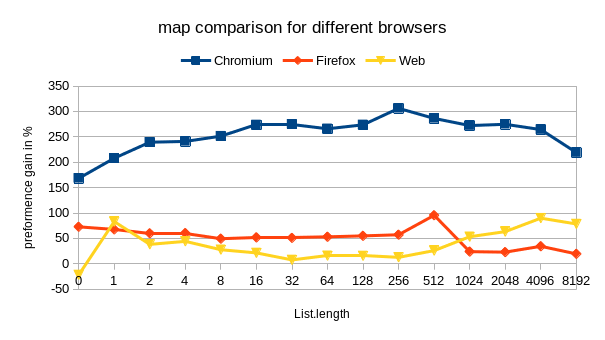
On Chromium this is slightly different and the benefits of the foldl version seem to start for lists larger than 500. Below that the original List.map seems to perfom better, but less than 5%. However on Firefox the results seem to be constantly better on average 25%.
Step 2
Only for curiosity, I added a local List.map1 function that does the same as List.map but it uses a Kernel function … The patches look like this:
-- ~/.elm/0.19.1/packages/elm/core/1.0.5/src/List.elm
...
map1 : (a -> result) -> List a -> List result
map1 =
Elm.Kernel.List.map1
...
// ~/elm/0.19.1/packages/elm/core/1.0.5/src/Elm/Kernel/List.js
...
var _List_map1 = F2(function(f, xs)
{
for (var arr = []; xs.b ; xs = xs.b) // WHILE_CONSES
{
arr.push(f(xs.a));
}
return _List_fromArray(arr);
});
...
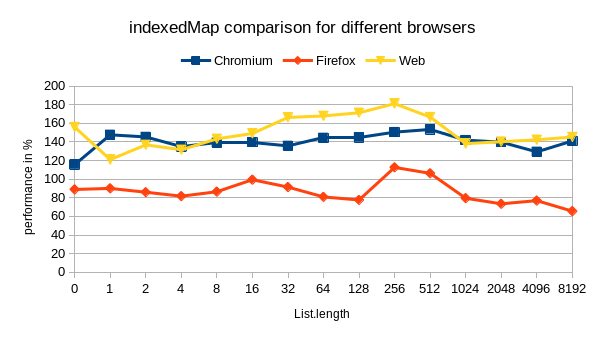
And boom, on Chromium I got a performance boost up to 250%, seems to be constant, tested for list lengths from 5 to 5000 … On Firefox, the results seem to be similar, however it is dropping from 250% to 60% on lists with a 5000 elements…
Conclusion
I have no idea which optimizations might be performed by the compiler with longer pipes of List.maps, etc. Although I had tested it with pipes also and it seems to be promising. But maybe this is an optimization that can be added to the core libs, not only into List …
Appendix
module Main exposing (..)
import Benchmark exposing (..)
import Benchmark.Runner exposing (BenchmarkProgram, program)
main : BenchmarkProgram
main =
program suite
map f =
List.foldl (\x acc -> (::) (f x) acc) []
>> List.reverse
suite : Benchmark
suite =
let
sampleList =
List.repeat 1000 0 |> List.indexedMap (\i _ -> i)
in
Benchmark.compare "Mapping"
"List.map"
(\_ -> List.map ((*) 2) sampleList )
"custom map"
(\_ -> map ((*) 2) sampleList )